Scraping Heroes of the Storm Competitive Information with Scrapy
I have previously written about my Glicko ratings of competitive Heroes of the Storm (HotS) teams, and how I put that information into a SQLite database. Up to this point though, I have been entering all of this information manually. In order to do the kind of analyses that I want to do, I really need to have access to a lot of data, and I really do not want to put all of into my database by hand.
I was also looking for an excuse to learn how to scrape websites for information and this seemed like the perfect opportunity to do it.
Enter Scrapy
I had a few requirements for my web scraper, although as usual the most important one was that the software is free and open source. I was looking for something in Python so that I would not have to learn a new programming language on top of a new tool. I also needed a scraper that could crawl the website for me so that I would not have to manually input every webpage.
The two big python packages in the web scraper world are BeautifulSoup and Scrapy (apologies to anyone working on something else). BeautifulSoup has a lot of built in tools to parse a webpage, but you have to know the webpages you want to scrape in advance. In the short term, this probably would have been a lot easier to use. Scrapy allows you to advance through pages automatically and is overall a far more robust tool than BeautifulSoup.
First Steps
There is a wonderful tutorial on using Scrapy on their website. I use Continuum's Anaconda Python, so the installation was as simple as
conda install scrapy. You might have to reboot to have scrapy added to your
PATH if you are using windows, but creating a Scrapy project is as simple
as
scrapy startproject hots
A Scrapy project starts out with the following structure
hots/
scrapy.cfg # configuration file
hots/
__init__.py
items.py # where you define your Scrapy items
pipelines.py # pipelines file, to put data in SQLite database
settings.py # settings file
spiders/ # directory where spiders eventually go
__init__.py
Picking a random match, here's what the initial spider looks like.
import scrapy
class HotsSpider(scrapy.Spider):
# Basic spider information
name = "hots" # does not need to match class name
allowed_domains = ["masterleague.net"] # variable name describes it well
start_urls = [
'http://masterleague.net/match/1918/'
]
def parse(self):
yield {
'match_date': response.xpath('/html/body/div/ol/li[6]/text()').extract_first()
}
All the spider is returning right now is the match date, which is a great first
start but there is a lot more to do. Scrapy can collect information using two
different methods: Xpath and CSS. While CSS can work fairly well, Scrapy's own
website believes that XPath is a far more powerful way of identifying content on
a webpage. The quick overview is that all you need to do to identify the xpath
is to open the website in chrome, right click on the data you want to extract,
select inspect element, right click on it in the source code, and click on copy
XPath. For a better overview of how to extract data using XPath, check Google.
The extract_first() pulls out the first element of the array it returns, but
can handle empty data.
Next, we will add an item to items.py to help with data processing.
import scrapy
class HotsItem(scrapy.Item):
# Basic match info
match_id = scrapy.Field()
match_date = scrapy.Field()
map_name = scrapy.Field()
home_team = scrapy.Field()
...
You should have a Field for every piece of data you want. I found it useful
to sketch out which fields I wanted first. If you want to see all of the
fields I actually ended up collecting, check out my github project. We need
to adapt the spider now to use the items.
import scrapy
from hots.items import HotsItem
class HotsSpider(scrapy.Spider):
# Basic spider information
name = "hots"
allowed_domains = ["masterleague.net"]
start_urls = [
'http://masterleague.net/match/1918/'
]
def parse(self, response):
item = HotsItem()
item['match_date'] = response.xpath('/html/body/div/ol/li[6]/text()').extract_first()
for match in response.xpath('//*[@id="draft"]')
# Scraping basic match information
item['map_name'] = match.xpath('div[5]/div[2]/span/text()').extract_first()
item['home_team'] = match.xpath('div[1]/div[1]/div/div[1]/h2/a/text()').extract_first()
item['away_team'] = match.xpath('div[1]/div[2]/div/div[2]/h2/a/text()').extract_first()
...
yield item
If you are unfamiliar with yield in Python, it is similar to return except
that it returns a "generator". A generator is an interable that can only be iterated
over once. If you want more information, check out this stack overflow page
Advancing Pages
The standard way of advancing pages in Scrapy is to identify some button like
'Next Page' through which you can get the url of the next page. Once there is
no more button, you end the scraper. Unfortunately, Master League
only links to the next game in a given series, but not does not link between
series. However, Master League increases the number of each match by 1,
which makes it easy to advance to the next page.
class HotsSpider(scrapy.Spider):
# Basic spider information
name = "hots"
allowed_domains = ["masterleague.net"]
start_urls = [
'http://masterleague.net/match/1918/'
]
def parse(self, response):
item = HotsItem()
...
...
prev_id = int(''.join(list(filter(str.isdigit, response.request.url))))
item['match_id'] = prev_id
next_page_url = response.request.url[:-5] + str(prev_id+1) + '/' # I will regret this
yield scrapy.Request(response.urljoin(next_page_url), callback=self.parse)
I was a little lazy though, for two reasons. The first is that I just replaced the
last five characters with the next match ID. Eventually they will hit match 10,000
I will have to fix the code. Second, the code ends whenever there is a 404 error,
which I never bothered to handle. It runs fine despite that though.
Adding Statistics
While the above information allowed me to create my Glicko ratings, I
eventually wanted to be able to do something like Moneyball for the
HotS competitive scene. Luckily, while I was working on this project,
Master League added statistics to their page. The statistics are loaded
using javascript when you click on the statistics tab. Interestingly,
they are just loaded from a webpage with the same URL as the match with
/stats/ added on. To get the data, I check whether the statistics tabs
exist and then use a second function to parse the data on the statistics
page.
import scrapy # The basis of everything
import re # Want this for extracting game num from url
from hots.items import HotsItem # The item I created earlier
class HotsSpider(scrapy.Spider):
# Basic spider information
name = "hots"
allowed_domains = ["masterleague.net"]
start_urls = [
'http://masterleague.net/match/1918/'
]
def parse(self, response):
item = HotsItem()
stat_check = response.xpath('/html/body/div/ul/li[3]/a/text()').extract_first()
if stat_check == 'Statistics':
request = scrapy.Request(response.request.url + 'stats/', callback=self.parseStats)
request.meta['item'] = item
yield request
The callback is now parseStats, at the end of which I go to the next match.
In order to pass the item with the basic information already in it, the item
is passed through request.meta['item'].
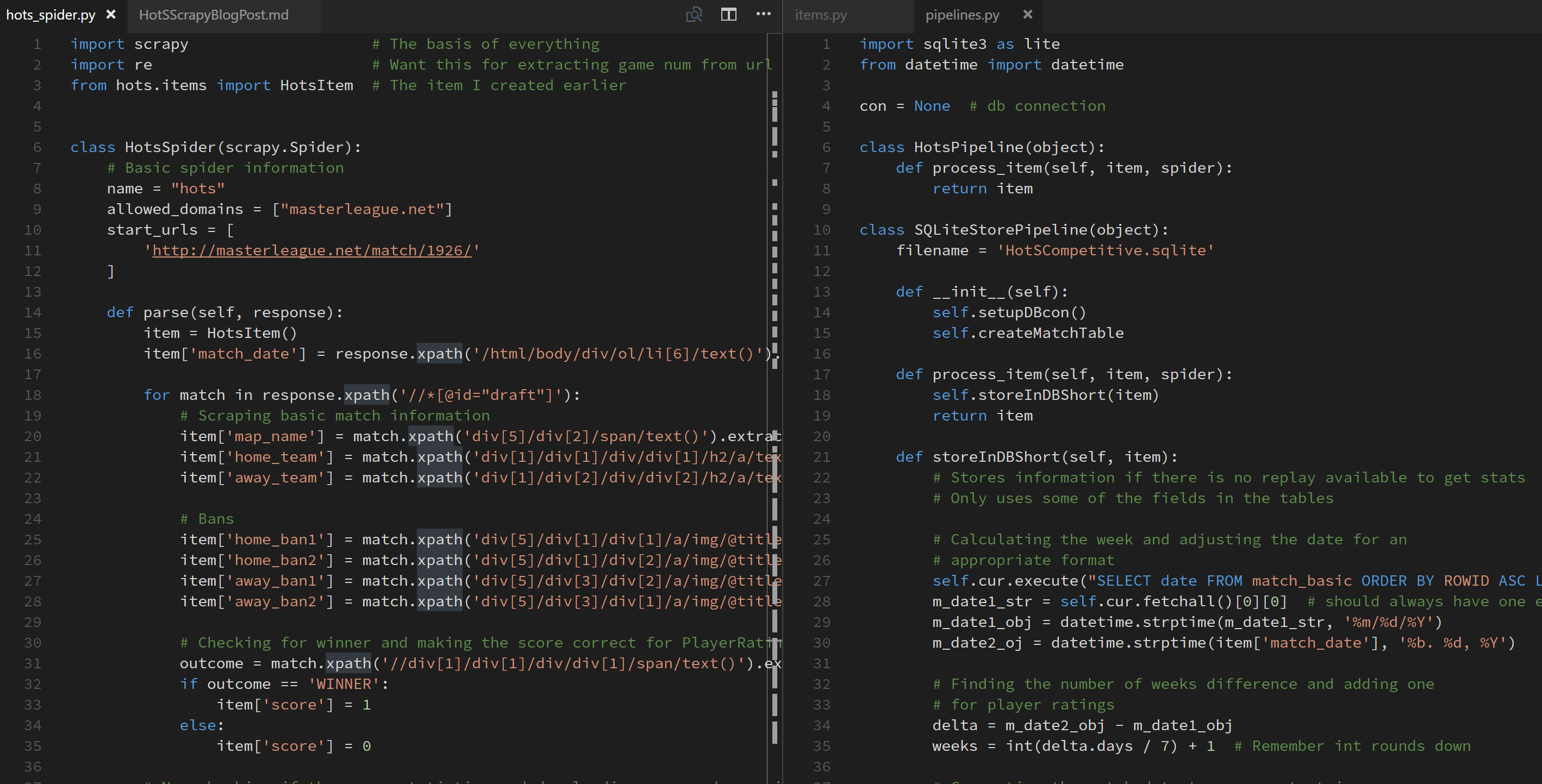
Pipelines
Most of what I learned about pipelines is from a
blog post I found using
Google. In pipelines.py, I created two class to store Items in the database
called HotsPipeline and SQLiteStorePipeline. I also converted the match date to
a more appropriate format and find the number of weeks since the first
match. Most important is to make sure the __init__ and __del__ are set
up so that the connection to the database terminates. Since only one process
can access a SQLite database at a time, this is crucial to being a good person.
import sqlite3 as lite
from datetime import datetime
con = None # db connection
class HotsPipeline(object):
def process_item(self, item, spider):
return item
class SQLiteStorePipeline(object):
filename = 'HotSCompetitive.sqlite'
def __init__(self):
self.setupDBcon()
self.createMatchTable
def process_item(self, item, spider):
self.storeInDBShort(item)
return item
def storeInDBShort(self, item):
# Stores information if there is no replay available to get stats
# Only uses some of the fields in the tables
# Calculating the week and adjusting the date for an
# appropriate format
self.cur.execute("SELECT date FROM match_basic ORDER BY ROWID ASC LIMIT 1")
m_date1_str = self.cur.fetchall()[0][0] # should always have one entry
m_date1_obj = datetime.strptime(m_date1_str, '%m/%d/%Y')
m_date2_oj = datetime.strptime(item['match_date'], '%b. %d, %Y')
# Finding the number of weeks difference and adding one
# for player ratings
delta = m_date2_obj - m_date1_obj
weeks = int(delta.days / 7) + 1 # Remember int rounds down
# Converting the match date to a correct string
m_date2_str = datetime.strftime(m_date2_obj, '%m/%d/%Y')
# Inserting the item into the database
self.cur.execute("INSERT INTO match_basic(\
match_id, \
...
away_ban2 \
) \
VALUES( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? )",
(
item['match_id'],
m_date2_str,
...
item['away_ban2']
))
self.con.commit()
def setupDBcon(self):
self.con = lite.connect('HotSCompetitive.sqlite')
self.cur = self.con.cursor()
def __del__(self):
self.closeDB()
def createMatchTable(self):
self.cur.execute("CREATE TABLE IF NOT EXISTS match_basic(\
match_id INTEGER NOT NULL, \
...
away_ban2 TEXT \
PRIMARY KEY(match_id) \
)")
self.cur.execute("CREATE TABLE IF NOT EXISTS `player_details`(\
`match_id` INTEGER NOT NULL, \
...
`exp` INTEGER, \
PRIMARY KEY(`match_id`) \
)")
def closeDB(self):
self.con.close() # definitely need to make sure conn closed
The only thing missing is that the first row of match_basic has to
exist already in order to calculate the date. While an if statement
could handle this, entering one row into a database I used to take care
of by hand is perfectly fine.
Next Steps
The code so far handles the vast majority of what I wanted it to, but
there are still some small additions left for quality of life
enhancements. The most important is Deltafetch as described on
Scrapy's blog.
The middleware keeps a list of the sites you have crawled so you do not
crawl them twice. This is great for both you and the site you are crawling.
Finally, make you adhere to the outlines in this post
on scraping politely. You don't want to have your IP address banned for
looking like a hacker, nor do you want to accidentally DDOS a website.
If you have a front-facing application, also be careful about any SQL
injection vulnerabilities. Since this will just be hosted on Github,
I was not particularly worried, but it is something you should always
consider.
For another practical crawler pattern, see how to use Scrapy with a fake user agent.